How to Create Text-to-Speech With Emotion in 7 Simple Steps
by Oliver Goodwin | April 13, 2023
Reading Time: 5 minutes

Text-to-speech technology (also known as speech synthesis) has been around for a long time. For context, the technology was invented in 1968. One would imagine that every platform associated with a technology that has been around for that long would have completed the cycle of human speech imitation by now.
Human speech imitation means all the attributes that give life to a voice and make it sound realistic, like tone, pitch, emphasis, volume, fluency, rate, and articulation. All these properties sum up what we call emotion in a voice.
Without emotion in an AI voice, it becomes just another monotonous speech. Nuance, which is the skeleton of speech, is usually lost. Imagine that you want to make an audiobook of your newly written fiction novel. An angry character would sound more violent than a character trying to lull another to sleep. AI voices bereft of emotion would not understand this and simply represent them the same way.
Do you now see how emotion-ridden AI voices challenge realism? As we progress in this article, we will touch more on text-to-speech with emotion. Prepare to learn:
- The importance of using emotion in your text-to-speech voiceovers.
- How to create text-to-speech voiceovers with emotion using Synthesys.
- Frequently asked questions (FAQs) and their answers.

The Importance of Using Emotion in Your Text-to-Speech Voiceovers
Research shows that speech synthesis with emotion performs significantly higher than without emotion. But that is everything about it. Let us take a deeper dive into the everyday applications of using text-to-speech with emotion:
Context Diversity
Words are diverse in form as well as in pronunciation. The pronunciation of a word depends on both the spelling and the context in which the word is used. Context, in turn, is demonstrated by emotion.
When you look at how text-to-speech works, focusing more on the text-processing stage, most AI speech synthesis systems simply see words as words. The situational contexts of said words are usually ignored. Hence, a sentence spoken in a business tone is expected to sound different from the same sentence spoken in a casual tone.
Heterogeneity of Business Settings
Business settings have different values and cultures. For example, a customer care scene where the voice tone is expected to be calm and reassuring should not have the same AI voice as a brokering department where the actions are hurried and aggressive.
A monotonous AI voice will collapse this heterogeneity and damage every attempt at uniqueness. On the other hand, adding emotion to your text-to-speech will give each business sector its appropriate AI voice.
How to Create Text-to-Speech Voiceovers with Emotion Using Synthesys
Creating your text-to-speech with emotion using Synthesys is easy and not as complicated as it sounds. So relax and follow the guidelines below:
Step One: Create an account
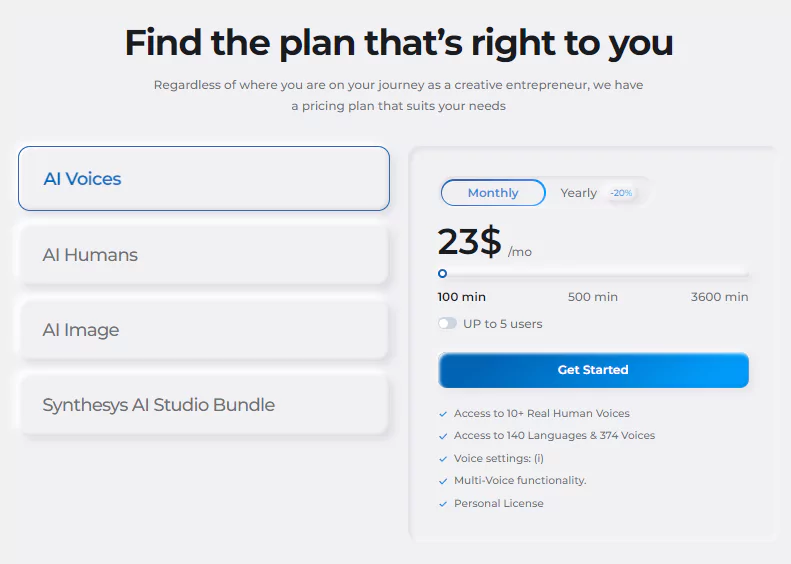
This is the preliminary stage. It is more like the documentation process you undergo before exploring an apartment you have just acquired. How do you do this? First, visit Synthesy’s text-to-speech tool page to view the available subscription plans. Choose the plan that fits your needs, and click on the GET STARTED button.
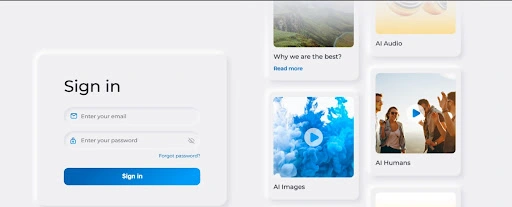
Step Two: Sign in to your Synthesys account
After you have completed the purchase of your preferred plan and have created an account, proceed to log in. And how do you do that? Go to Synthesys’ live studio login page and enter your login credentials.
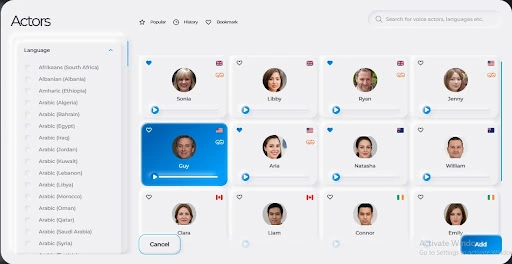
Step Three: Choose your preferred language and accent
Synthesys has over 140 languages plus 300 unique accents from which you can choose. This is because words are pronounced more accurately in their language. A Spanish word, for instance, would never be pronounced accurately in English. Likewise, an English word pronounced in Australia would sound different from the same word pronounced in Nigeria.
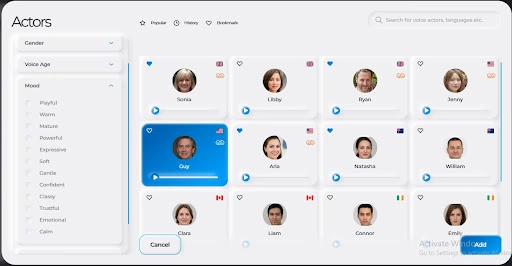
Step Four: Choose your preferred voice and mood
This step is the most important. This is where you decide the gender, age, and mood of your voice actors. Synthesys has a bank of 451 human voice ambassadors. This mood is the centerpiece of this post. In total, there are 12 different moods available, namely: playful, warm, mature, powerful, expressive, soft, gentle, confident, classy, trustful, emotional, and calm. You also get to choose the type of content you intend to create with the voiceover.
Step Five: Enter your script
You can do this either by copying your script from the notepad on which you’ve written it and pasting it in the textbox provided (see below) or by typing it directly into the text box.
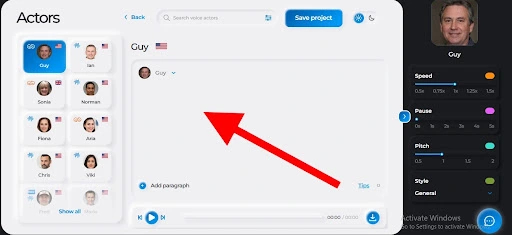
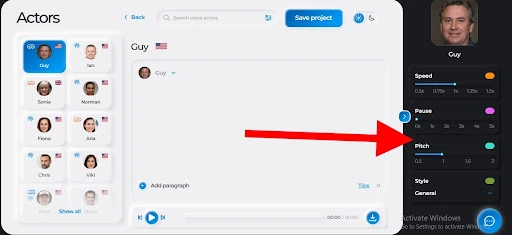
Step Six: Adjust your audio properties
These properties include speed, pause, pitch, and style. The speed controls how fast your speaker talks. The pause controls how long your speaker pauses at every period, comma, and semicolon. The pitch helps you adjust the frequency of your audio file. And finally, style contains options such as angry, cheerful, sad, excited, etc.
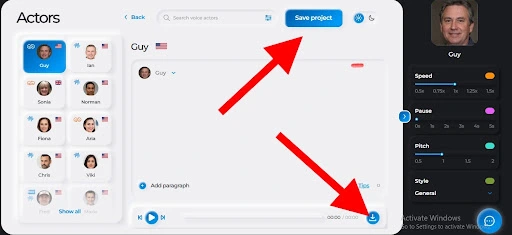
Step Seven: Download your audio file
After you have played your audio file and are satisfied with it, click on the SAVE PROJECT button and, subsequently, the download icon. Your will file will be downloaded into the selected folder.
Frequently Asked Questions
Here are the two most frequently asked questions about creating text-to-speech with emotions:
What is the best way to add emotion to my voiceovers?
By using Synthesys text-to-speech tool. Once you have created your account, you will have a chance to choose which mood best reflects what you are working on. Then, follow the guidelines above to add emotion to your voiceovers.
Does Synthesys have enough mood options to fit any description that I want?
Yes. Synthesys has over 74 unique moods you can pick from. These options are all-encompassing and cut across as many scenarios as possible.
Wrapping Up
The world is advancing rapidly towards a scene where AI makes guaranteed 100% efficiency a reality. Therefore, risking homogeneity, especially in the speech synthesis space, is likely counterproductive to AI’s purpose in the same space.
Bringing emotion to the scene will ensure reality and diversity. And how do you do that? By using an appropriate text-to-speech tool with natural voices, such as Synthesys.
Synthesys realistic voices brings truth to your voiceovers and makes your process seem lifelike.



