Personalising Your Text-to-Image AI Generation
The world is full of rare wonders, and text-to-image AI technology is undoubtedly one of them. Being able to generate random images by entering the…

The world is full of rare wonders, and text-to-image AI technology is undoubtedly one of them. Being able to generate random images by entering the corresponding text prompts used to be a fantasy, but no more.
Text-to-image AI models such as Synthesys Visual, DALL-E, DALL-E 2, Imagen, and Parti transition imagination into reality through several AI tools, and they do this masterfully well. The interesting part of this process is the chances of getting your desired results are high. For example, say you require the image of two aliens having a dinner date on a cruise ship; you can rest assured that you will get multiple variants of this subject.
However, there could be more. There will always be more possibilities, which is the beauty of technology. The text-to-image technology that we are familiar with comes with two limitations:
- They are restricted to taking only text prompts.
- They are incapable of personalizing images to our taste.
Using text-to-image AI for recreational purposes or to grow your business ought to come with unfettered freedom. The above limitations, however, defeat this notion. If, for instance, you wanted to model a cartoon character after yourself or transform an image of your cat into a painting, the traditional text-to-image AI would have no way around such customizations. But with recent developments, you can achieve those and more. So, what are these recent developments?
“An Image Is Worth One Word”: Personalising Your Text-to-Image AI
Researchers from Tel Aviv University and NVIDIA worked on developing new roles for text-to-image technology that have the potential to change the game forever.
The concept, broadly discussed in a paper termed An Image Is Worth One Word, is a novel idea that extends the capacities of the traditional text-to-image AI beyond its weaknesses. It aims to give content creators and business owners all the creative licenses they need to generate any image they require. The objectives include:
- Generating images of distinct concepts that are specific to the user’s intent.
- Modifying images following the user’s preferences.
- Defining images in a new light—creating new roles for them or immersing them in new environments.
How Does This Model Work?
The model resembles the already established text-to-image models across technical lines but with slight tweaks. It uses a pre-trained text encoder model, which typically takes only text input and incorporates a latent diffusion model to enhance its input flexibility. The latent diffusion model is the bedrock of this concept as it enables heterogeneous kinds of input to breed robust syntheses such as text-to-image, image-to-image, or a combination of both.
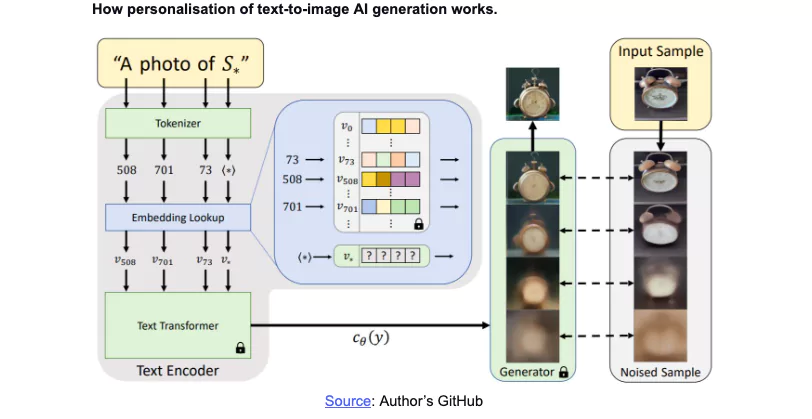
The generator begins by receiving an input of three to five images of the subject, say images of yourself, which you want to redesign. Then, the text encoder model creates “pseudo-words” of the input images, while the latent diffusion model forms representations of these images into encoded images.
Next, the text encoder is trained to match its pseudo-words to the encoded images in a “Textual Inversion” process. The process is summarised in the image below:
Applications of This Model
Although the model is still in its formative phase, it has promising applications and their corresponding benefits:
Style Representation
In the same way that writers infuse voice in their writing to flaunt their unique identities, artists and brands also possess their identities. Think Claude Monet, Pablo Picasso, Coca-Cola, etc. These personalities are easily recognizable because of their unique painting or marketing styles, and uniqueness is a vital function of marketability.
Unlike the traditional text-to-image AI models, this model grants you the freedom to insert your brand or creator identity into your designs.
Bias Reduction
Existing text-to-image models are subject to being confused and, therefore, stuck when they encounter new or untrained words. However, you are less likely to face this challenge when you personalize your text-to-image using this upcoming model, as it simply finds new embeddings for the controversial entry.
Integrating Downstream Models
The model works well with downstream models. In other words, it can blend two or more distinct images from different timelines into one. So, for instance, you can integrate people in your life now into old images of you. Create magic.
Novel Ideations
The concept is not restricted by reality. Anyone can create new scenes that have never been seen before.
Conclusion
Flexibility is a sine qua non of business and technology, and text-to-image AI happens to be where both areas experience confluence.
This new model has prospects that have never been seen and will take creativity to a new realm of originality, flexibility, and timelessness.
Keep reading
All posts →
Can You Monetize Youtube Videos with Text-to-Speech Al Voices?

How to Grow Your Business Using Text-to-Image AI Generators

AI avatar quality in 2026: what actually matters