Everything You Should Know About Text-to-Image AI Generators
Sometimes, words are never enough to describe the things you want to say. At other times, words prove too long, and in the end, this defeats the entire…

Sometimes, words are never enough to describe the things you want to say. At other times, words prove too long, and in the end, this defeats the entire purpose of accurate description. This paradox exists in the minds of diverse professionals, from business owners to creatives. So, how would you deal with it should you encounter it? An effective strategy is the use of imagery.
The human brain processes images almost 60,000 faster than text. As a result, the appropriate image extends your reach beyond the capacity of your words. Despite the added benefits of deploying imagery, the processes involved in creating the perfect image can be arduous and time-consuming. But what if there were a quicker and easier way to achieve this? This is where a text-to-image AI generator comes in.
What is Text to Image AI?
Imagine being able to conjure up any image that vividly describes your imagination by simply entering the text. For instance, you can generate the image of a cat eating a strawberry in less than ten seconds by entering “cat eating a strawberry” into the required textbox.
“Image of a cat eating a strawberry” generated from Deep AI using text.

Text-to-image AI uses deep learning models trained on large image datasets—big data analytics—following their textual descriptions to produce high-quality synthesized images with more extensive descriptions. That is a huge amount of data considering the number of image components that must be synthesized with the corresponding text and in agreement with the syntactic context.
For instance, the sentences “A man pulling a dog.” and “A dog pulling a man” have the same words but are arranged differently. Text-to-image AI models are saddled with the responsibility of telling the nuances between these two textual descriptions and producing images that perfectly match the two.
What are the Leading Text to Image AI Models, and How Do They Work?
The four prominent text-to-image AI generators come from two tech giants: OpenAI—with its DALL-E and DALL-E 2; and Google— with its Imagen and Parti.
DALL-E
DALL-E is a subset of OpenAI’s GPT-3—an autoregressive machine learning language model trained using 175 different parameters. Specifically, DALL-E was trained with 12 billion of these parameters.
DALL-E 2
Over a year after DALL-E was released, OpenAI released a more enhanced version—DALL-E 2. This model offers a resolution four times greater than its predecessor’s. In addition, it produces images that are expandable beyond the original canvas and makes realistic modifications to images without injuring properties such as shadows, textures, and reflections.
GIF showing how it works
!
Source: Medium
Below is a summary of how the model generates its image from a text prompt:
- A text encoder receives the text input and creates text embeddings.
- The text embeddings are used to create correlating image embeddings through the Prior model.
- An image decoder generates images from the embeddings.
Details of DALL-E 2 image generation process
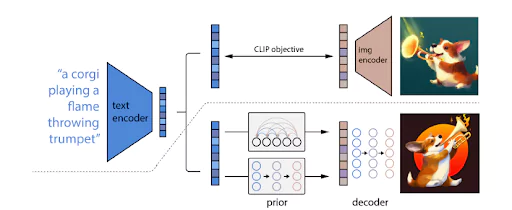
Source: OpenAI
Imagen
Unlike most other models, Imagen is pre-trained on text data only; how? It deploys a Transformer (important architecture responsible for applications such as text-to-speech voice generators) language model to transform the text input into a series of vector embeddings.
Parti
Parti is a sequence-to-sequence model built around the transformer, just like Imagen. It deploys an encoder-decoder method of processing text inputs and autoregressively anticipating discrete image tokens. The designated image tokenizer, ViT-VQGAN, processes these predictions and finally generates a photorealistic image.
A breakdown of Parti’s mode of operation:
- The model collects a library of images and converts them into a sequence of code entries.
- Text inputs are interpreted and translated into m code entries, generating the image as the final output.
What are the Applications of Text-to-image AI?
One attractive property of this technology is its vast range of use cases. Think of it as a necessity anywhere images are used. This, in effect, means text-to-image AI generators may become indispensable in the near future as they can be used in:
- **Creating cartoon characters—**for comic artists.
- **Designing logos and brand images—**for business owners.
- **Generating illustrations, stock photos, and concept art—**for digital art commercial purposes.
- **Visualizing architectural and interior design concepts—**easing the work process of structural design and beautification.
- **The ideation process that concerns visual work—**can become tedious, having to express every perceived concept manually. Text to the image makes this super easy and fast.
- **Creating comic books and animation models—**as references for a broad present and future application.
- **Generating realistic backgrounds—**used in graphic design and photography.
**Accentuating ideas and messages—**used on digital platforms and in print to enhance textual descriptions through visuals.
How to Convert Text to Image
The text-to-image models have birthed numerous web tools placed at your disposal for easy access and navigation. Here are some of the most popular of those tools:
- Starry AI
- Synthesys AI Studio
- Dream by Wombo
Visit your preferred platform, enter your thoughts into the appropriate textbox, and watch your imagination unfold. Then, download the image generated in the format and resolution of your choice.
What are the Benefits of Using Text to Image AI Generators?
If AI text-to-image models were not beneficial to the tech industry, they would have been phased out. Below, we explore the diverse benefits of adopting AI Text to Image AI generators.
You Can Finally Be Your Artist
Creating and telling amazing stories through pictures requires in-depth knowledge of graphic design. But that is about to change forever. With AI text to image, all you need are your imagination and the words to describe them, and the image you seek will come to you.
Imagine the Speed and Ease
Using these AI text-to-image tools requires far less effort and time than creating your design from scratch. This leaves you with maximum effort and time, which you can channel elsewhere. It typically takes less than three minutes to generate the images.
Increased Productivity
For instance, a business owner deploying text-to-image tools to create their design would never have to hire an extra hand to help with the image design or waste resources that could have been funneled to another place.
Furthermore, you stand to profit from the dividends of enhanced user experience on your platform.
You Don’t have to Worry About Making Mistakes.
Worries about making mistakes can be a preventive measure against creating the right and needed visuals. You do not have to let that hinder you because text-to-image AI delivers exactly what it is told to with few to no blemishes.
Conclusion
The world is spinning faster with technology, and as its inhabitants, we are expected to spin with it if we must catch up. This involves capturing the latest developments in the technology market and aiding ourselves and our businesses as we advance into the future.