What is Neural Text to Speech?
by Oliver Goodwin | September 28, 2022
Reading Time: 8 minutes

If you frequently use digital devices or the internet, chances are you have encountered Text-to-Speech (TTS) or Read Aloud technology at some point. Activities such as requesting that CAPTCHA challenges be read out loud, getting map directions while driving, listening to your favorite audiobook, etc., are enabled by TTS.
TTS is an assistive technology that uses artificial intelligence (AI) to model natural language to produce audio formats of digital texts. The traditional TTS is a product of concatenative synthesis—stringing pre-recorded voice samples together. This technique, however, sometimes creates listening fatigue owing to the presence or absence of speech parameters and sound attributes such as homonyms, prosody, speech flow, loudness, the intensity of overtones, etc., that human voices incorporate.
These imperfections are what neural text-to-speech aims to smoothen. Neural TTS uses a neural network—an AI method modeled after the human brain—to convert phonemes into a wave of spectrograms. Just like the brain does not require rules to obtain and apply knowledge, neural TTS is the product of training a TTS model using machine learning (ML) to learn from voice input without hard-coded rules.
The output is a speech development that sounds more realistic and lifelike. Neural TTS allows you to listen to and interact with a computer while giving the impression that you are talking to an actual human.
What Are the Characteristics of Neural Text-to-Speech?
The traditional TTS disintegrates prosody into multiple linguistic parts and sonic predictions that independent models control. Neural TTS, on the other hand, simultaneously predicts prosody and synthesises voice, and it performs these functions using two key components: a neural network and a neural vocoder
The Neural Network
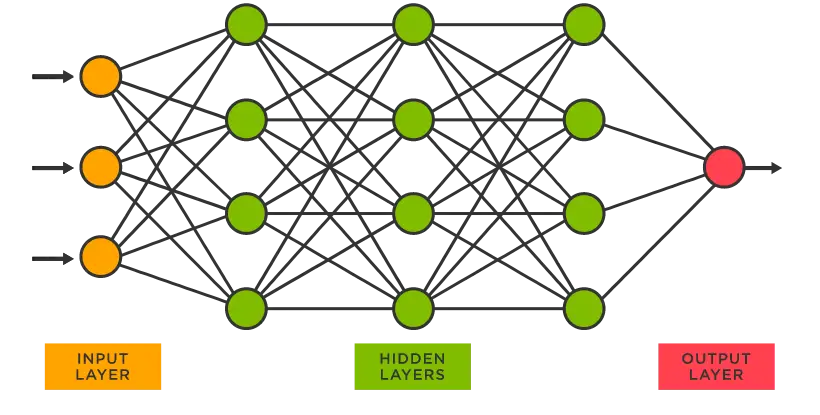
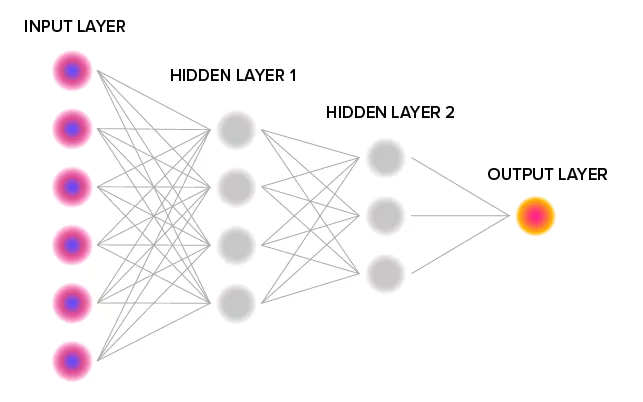
A neural network is an AI method that trains computers to absorb and process information the way the human brain would. It is what forms the deep learning aspect of ML, and just like the human brain, it is made up of interconnected neurons in a structured format. With this complex network of neurons, computers can learn from their mistakes through data reinforcement until they have attained perfection.
In neural TTS, the neural network transforms an arrangement of phonemes into spectrograms. These spectrograms are visual representations of sound frequencies at different energy levels. They make it easy to record prosody, loudness, signal strength, etc.
A neural network typically comprises three primary layers: the input, hidden, and output layers.
The Input Layer
This is where the artificial neural network workflow begins. This layer contains the artificial input neurons into which the data is passed for processing. The unique attribute of this part of the neural network is the speciality of each artificial neuron. Each neuron plays a role different from the other in the received data, and collectively, they transfer the data to the hidden layers.
The Hidden Layers
The intermediary layer is where all simulations of the human brain happen. The hidden layers are structured in two major ways: Random Assignment and Backpropagation.
In Random Assignment, data from the input layer is randomly split among the hidden neurons and trained. Backpropagation, on the other hand, means the backward propagation of errors. In this method, input data is fine-tuned through iteration between the hidden and output layers until the desired result is achieved.
The Output Layer
The final layer from which results are perceived. Here the desired results are compared with processed data received from the hidden layers and, if they have not been achieved, are sent back to the hidden layers for further fine-tuning (backpropagation).
The Neural Vocoder
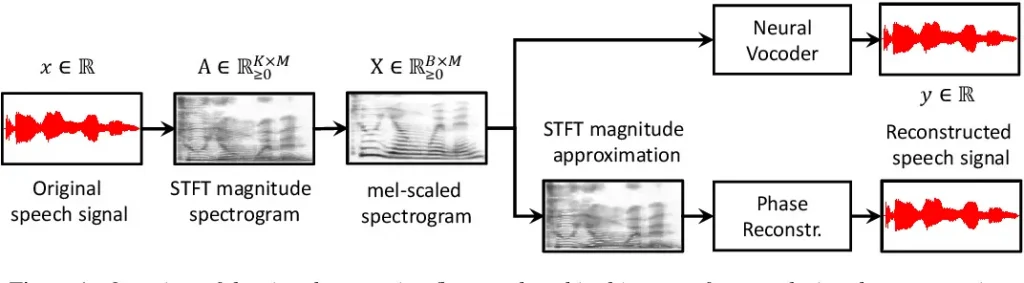
Spectrograms are usually the results retrieved from the neural network’s output layer. But they are difficult to interpret by the human sense organs and must be converted to usable formats for proper utilisation. This is where the neural vocoder comes in.
A neural vocoder receives the spectrograms from the output layer and transforms them into speech waveforms. The speech waveforms are continuous two-dimensional graphs representing the received sound’s time and intensity. This approach enables the vocoder to pick minute details in the processed sound to recognise all aspects of the human voice relating to written texts. After this last training phase, the final output is an ultra-realistic voice that is hardly distinguishable from an actual human voice.

What Models Does the Neural Text-to-Speech Use?
All concepts require a medium to come to life. Just as the brain needs a body to function, neural TTS requires a body to become fully applicable. In this case, the body is a model.
Unlike in traditional TTS, where human voice samples are strung together to devise pronunciations, the neural TTS creates human voice simulators that talk to you from your devices and sound seamlessly like humans. How is this possible? Neural network models.
The neural network speech models or deep neural network (DNN) models are hosts that take the human voice samples, clone them, and convert text to speech using the already cloned voice samples. If you listened to the output, you would hear the sample voice presenting the text passed in. But to make this voice output a success, at least three different models are needed: the acoustic model, the pitch model, and the duration model.
The Acoustic Model
This model establishes the connection between any given audio signal and the phonemes that compose speech. In this case, the audio signal is the recorded voice.
It essentially breaks down the sample voice into phonemes, which are then converted to spectrograms. The spectrograms are afterwards studied for certain properties: quality or timbre. Finally, the timbre—which distinguishes two or more audio signals with the same frequency—is compared with the timbre of the phonemes that constitute speech.
An acoustic model is trained by receiving the audio recordings of the voice sample, getting the text transcriptions of words included in the recordings, and creating statistical figures of the sounds or phonemes that make up every word.
The Pitch Model
The quality of speech is only one of the things that must be learned and predicted to achieve a perfect simulation of the human voice. Another attribute of speech that must be factored in is its pitch; you can effectively learn this with a pitch model.
Upon getting voice samples and studying the acoustic variance in tones, the pitch model predicts pitch outlines or curves during interference. After that, it generates controllable speech by applying the predicted curves.
This model, in essence, can exhibit the perceived emotional states of the writer of a given text and other prosodic properties. It also understands emphatic contexts in embedded texts based on frequency outlines of previously analyzed voice samples.
The Duration Model
Written texts transfer the nuances they possess to speech. Thus, the lengths of breath needed to pronounce “bin” and “been” differ despite the similarity in their pronunciations. To pronounce words as accurately as they come, neural TTS requires another unique model: the duration model.
The duration model predicts the length that each phoneme stays in a breath. It performs positional analysis on the different arrangements of speech—phonemes, syllables, and words. The duration model makes up the prosodic model with the pitch model.
Together, all three models determine the sound you hear from your text to speech service or software application.

What Can Be Achieved With Neural Text-to-Speech?
Neural TTS has as wide a range of applications as traditional TTS. However, the unique possibilities that can be achieved with neural TTS far transcend the capabilities of traditional TTS. Besides providing models for ultra-realistic, natural sounding voices, it offers more advantages, which are discussed below.
Enhanced Voice Flexibility and Scalability
Traditional TTS typically provides monotonous, robotic voices and is restricted to certain applications. For instance, you can only use a male voice sample in cases where a rigid male voice is required.
With a neural TTS system, however, a software application can represent every version of the human voice and speaking styles, incorporating all nuances of emotion needed to convey relevant meanings. Business enterprises can leverage this to improve their customer care representation, close deals, and apply to audio files of written books or advertisements that appeal to wider, more variegated audiences.
Data Security and Storage Optimisation
One of the major drawbacks of traditional TTS is the volume of data that must be stored and protected. Each voice sample has its storage cache, and these caches can both be cumbersome and prone to destruction. This puts an entire organisation that may have built its marketing leverages on them at risk of a loss.
Neural TTS removes this challenge easily through transfer learning. Transfer learning is a process in ML where a solution to one problem can be transposed onto other problems and can be used to solve them. This erases the need for multiple data storage requirements.
Cost-Effective and Low-Effort Speech Synthesis
With transfer learning, it does not cost as much as it would in traditional speech synthesis to train data and achieve the desired results. The effort and cost needed to get large datasets and the time it takes to record tens of samples are significantly reduced. With neural TTS, you invest less and get better results. With only a few short recordings, you can conjure simulations that will produce more realistic voices than traditional TTs would have yielded.
Prosody Transfer
Prosody transfer is a method in speech synthesis used to transpose the prosody from an audio source onto a speech being synthesized. If two neural voices exist in similar language and pitch ranges but with different styles and sounds, you can use prosody transfer to move the properties of one of these voices to the other if you require it.
Language Independence
Another limitation that comes with the traditional TTS is language dependence. For instance, a voice sample taken in English would perform woefully if it were required to read a text written in Spanish. Why? The variance of pronunciation rules between both languages is wide.
In neural TTS training, the pronunciation possibilities that are taken into account are huge. And not only do they not require an original sample to be trained, but they also cover as many languages as possible with as few as twenty samples trained.
This advantage is especially useful to translators, owners of language academies, and for developing language learning apps.
Wrapping Up
The technology behind neural text-to-speech is deep learning. As of 2021, the global deep learning market was valued at $2.67 billion. This figure is projected to rise to $11.9 billion by 2028, with a compound annual growth rate (CAGR) of 23.6% between 2022 and 2028. The global text-to-speech software market size, valued at $2.54 billion as of 2021, is projected to reach $5.79 billion in 2028, with a CAGR of 12.3% between 2022- 2028.
The statistics and projections indicate the apparent global adoption of TTS technology and neural TTS. Furthermore, the wide-ranging applications of this technology have established it as a certainty in the foreseeable future.
Furthermore, while the only advantage traditional TTS might have over neural TTS is the service pricing, the advantage is defeated when the benefits are considered. Neural TTS not only offers all the benefits that traditional TTS offers but also solutions to the numerous limitations that accompany traditional TTS. If you want a high-quality neural TTS software visit our AI voice generator page and try it for free.



